

如何用python爬取网站数据?
安装Python和相关库 要使用Python进行网页数据抓取,首先需要安装Python解释器。可以从Python官方网站并安装最新的Python版本。安装完成后,还需要安装一些相关的Python库,如requests、beautifulsoup、selenium等。
用python爬取网站数据方法步骤如下:首先要明确想要爬取的目标。对于网页源信息的爬取首先要获取url,然后定位的目标内容。先使用基础for循环生成的url信息。
以下是使用Python编写爬虫获取网页数据的一般步骤: 安装Python和所需的第三方库。可以使用pip命令来安装第三方库,如pip install beautifulsoup4。 导入所需的库。例如,使用import语句导入BeautifulSoup库。
思路如下:使用urllib2库,打开页面,获取页面内容,再用正则表达式提取需要的数据就可以了。下面给你个示例代码供参考,从百度贴吧抓取帖子内容,并保存在文件中。
如何通过网络爬虫获取网站数据?
1、基于API接口的数据采集:许多网站提供API接口来提供数据访问服务,网络爬虫可以通过调用API接口获取数据。与直接采集Web页面相比,通过API接口获取数据更为高效和稳定。
2、以下是使用Python编写爬虫获取网页数据的一般步骤: 安装Python和所需的第三方库。可以使用pip命令来安装第三方库,如pip install beautifulsoup4。 导入所需的库。例如,使用import语句导入BeautifulSoup库。
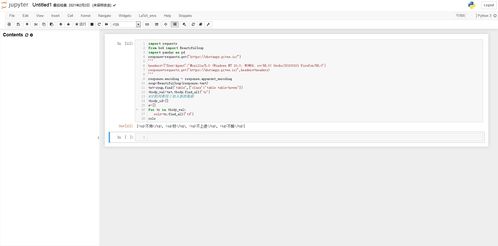
3、设置翻页规则。如果需要爬取多页数据,可以设置八爪鱼采集器自动翻页,以获取更多的数据。 运行采集任务。确认设置无误后,可以启动采集任务,让八爪鱼开始爬取网页数据。 等待爬取完成。
4、以下是网络爬虫的入门步骤: 确定采集目标:首先需要明确你想要采集的数据是什么,以及数据来源是哪个网站或网页。 学习HTML和XPath:了解HTML和XPath的基本知识,这是进行网页解析和数据提取的基础。
5、数据采集的方法和技巧有很多种,以下是一些常用的方法和技巧: 使用网络爬虫工具:网络爬虫工具可以帮助您自动抓取网页上的数据。
Python编程基础之(五)Scrapy爬虫框架
建立一个Scrapy爬虫工程,在已启动的Scrapy中继续输入:执行该命令,系统会在PyCharm的工程文件中自动创建一个工程,命名为pythonDemo。
· 器中间件(Downloader Middlewares): 位于Scrapy引擎和器之间的框架,主要是处理Scrapy引擎与器之间的请求及响应。
Scrapy是一个轻量级的使用Python编写的网络爬虫框架,这也是它与其他Python框架最大的区别。因为专门用于爬取网站和获取结构数据且使用起来非常的方便,Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试等等。
如何用python实现网络爬虫
使用Python编写网络爬虫程序的一般步骤如下: 导入所需的库:使用import语句导入所需的库,如BeautifulSoup、Scrapy和Requests等。 发送HTTP请求:使用Requests库发送HTTP请求,获取网页的HTML源代码。
三行 网络爬虫是指通过自动化程序去获取互联网上的信息和数据,一般需要使用编程语言来实现。在 Python 中,使用第三方库 requests 和 BeautifulSoup 可以很轻松地实现一个简单的网络爬虫。
从爬虫必要的几个基本需求来讲:抓取 py的urllib不一定去用,但是要学,如果还没用过的话。比较好的替代品有requests等第三方更人性化、成熟的库,如果pyer不了解各种库,那就白学了。抓取最基本就是拉网页回来。
学习Python爬虫库:Python有很多优秀的爬虫库,如Requests、BeautifulSoup、Scrapy等。可以选择其中一个库进行学习和实践。 实践项目:选择一个简单的网站作为练习对象,尝试使用Python爬虫库进行数据采集。
pyspider 是一个用python实现的功能强大的网络爬虫系统,能在浏览器界面上进行脚本的编写,功能的调度和爬取结果的实时查看,后端使用常用的数据库进行爬取结果的存储,还能定时设置任务与任务优先级等。
一般来说,编写网络爬虫需要以下几个步骤: 确定目标网站:首先需要确定要抓取数据的目标网站,了解该网站的结构和数据存储方式。
希望这篇文章能为您带来启示和帮助,如果您有任何问题或建议,欢迎随时与我们联系。







